Large Language Models (LLMs) like Chat-GPT have shown impressive capabilities in natural language understanding and generation. However, they come with inherent limitations—most notably, they are closed systems trained on static datasets. This means they lack real-time awareness of new information, often struggle with factual accuracy, and cannot access private or domain-specific data out-of-the-box. For companies building AI-driven SaaS products, this is a critical gap. Regardless of industry, whether it’s legal, information technology, healthcare, finance, or customer support, applications need to deliver answers grounded in current, reliable, and context-specific data.
This is where RAG (Retrieval-Augmented Generation) comes in. RAG enhances an LLM’s response by combining it with a retrieval system that fetches relevant resources, such as documents or data chunks from external knowledge at the point of inference. Instead of relying solely on the model’s static dataset and parameters, RAG enables it to dynamically access fresh (more up-to-date) and grounded information. This greatly improves not only the relevance of responses but also their accuracy of said responses to user queries. For instance, a legal AI assistant can reference up-to-date case law, or, a customer support bot can cite a company’s most recent policy documents; a healthcare assistant can reference the latest research studies; all of which are in addition to the static and closed LLM training dataset.
This naturally leads to the question how can we retrieve relevant and more up-to-date knowledge for LLM consumption? There is a widespread interest and debate on the subject, landing at two prominent approaches: Vector Databases and Knowledge Graphs. Both aim to solve the same core challenge—efficiently retrieving the right context to feed LLMs—but they do so in fundamentally different ways. Understanding the strengths and trade-offs for each method is crucial to building effective, scalable RAG pipelines needed to solve this problem. In this post, we’ll unpack the key differences between these two paradigms and tackle the hotly debated question: which approach, VectorRAG or GraphRAG truly delivers the best results for real-world AI applications?
Vector Databases in a nutshell
Imagine a vector database like a super-smart librarian who organises information in a special way. Instead of storing books as plain text, it turns everything—text, images, or other media—into a kind of numerical code called a “Vector.” These vectors are like fingerprints that capture the meaning of the information. They’re created using tools (like BERT or SentenceTransformers) that understand the essence of words or data.
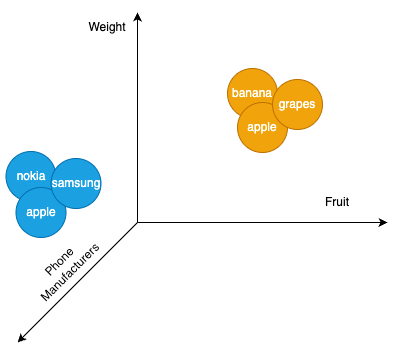
In vector databases words with similar meaning or context will have vectors that are close together, while unrelated words will be further apart. Therefore distance or angle between vectors are used to gauge the semantic similarity between words and phrase. For example think about phone manufacturers and types of fruit. Nokia, Samsung, and Apple —belong together as they share same meaning in the context of ‘phone’. Whereas fruit—like bananas, grapes, and apples—form a different group, even though the word “Apple” appears in both.
Let’s say you type: “Apple phone” into a search box.
Now here’s the catch:
“Apple” can mean a fruit
Or the famous technology company that makes iPhones
A traditional search engine might just look for the word “Apple” and return both types of results fruit facts and other brands of phones — because it doesn’t understand what you mean, it doesn’t know the full context from the user’s query.
As part of the preparation when creating the vector database, vector transformers, as mentioned above, work their magic in converting text and other media into a multidimensional vector model. This model can be used to query against, just like a database – it is important to remember in this context, everything is converted to vectors, not left as text.
This is where semantic search powered by a vector database comes in. In semantic search, searching with the text “Apple phone” is converted to vector. This vector search ‘lands’ in a similar position to nearby vectors within the database. This means “Apple phone” is going to land near to “phones” (blue circles in above diagram) and in this case those similar vectors are other phone manufacturers (Nokia, Samsung etc).
Knowledge graph in nutshell
Think of a knowledge graph as a digital map that connects ideas, facts, and entities like a web of relationships. Instead of just storing data as raw text or numbers, a knowledge graph organizes information into nodes (things) and edges (relationships between things). Each node represents an entity—like a person, company, or object—and each edge describes how they’re linked, such as “produces,” “is a type of,” or “is related to.”
The image below is a simple example of a knowledge graph. It consists of two nodes connected by an edge. The first node, labeled “Company: Apple,” represents the entity Apple, a well-known technology company. The second node, labeled “Phone: Model: Pro”, represents a specific phone model, “ModelPro.” The edge between them, labeled “PRODUCES,” indicates the relationship that Apple produces the Model:Pro phone. This visual representation illustrates how a knowledge graph links entities (nodes) with their relationships (edges), providing a clear and structured way to understand connections between data points.

Vector RAG Vs Knowledge graph RAG
Imagine you’re building a news aggregator application that quickly finds articles matching a user’s query, like “latest tech breakthroughs.”
VectorRAG (Vector databases for RAG) is perfect for this because it’s fast, scalable, and great at understanding the meaning of text.
Why it’s easy?: For these text-based articles, there is no requirement to ‘clean’ and much less structuring (a common step involved in Machine Learning) is needed . Tools like BERT, SentenceTransformers, or other pre-trained models (available in libraries like Hugging Face) read each article and can transform these into vectors in seconds. Modern vector databases like Pinecone, Weaviate or Chroma can easily spawn up and feed vectors into it just easy as few clicks. You don’t need to be a tech wizard!
However in this process of vectorisation there is a risk in losing this deep relational understanding; it can’t easily link cause-and-effect, nor follow chains of related facts across articles; this is where knowledge graphs excel.
GraphRAG (Knowledge Graphs for RAG) shine in domains with structured, relational well-defined data where precision and reasoning are critical. When working with LLM’s sometimes we expect not just a direct answer but a richer and deeper picture of the full story. This is achieved by harnessing additional context by traversing relationships provided by the natural knowledge graph. For example within a healthcare app if user asks, “What treats Diabetes?” the knowledge graph doesn’t just search for keywords. It follows the connect relationships relevant to “Diabetes” to find precise answers, like “Insulin” or “Metformin”. It can go further, proactively pulling in related useful information, such as – “Diabetes may lead to Kidney Disease”, by tracing and traversing the graph finding more connections.
However building these knowledge graphs is not easy task. It involves proper planning, domain expertise, maintenance complexity and large overheads, requiring strong disciplined governance.
Final Thoughts
While VectorRAG excels at capturing the semantic meaning of queries and content—making it ideal for initiating LLM-powered conversations—its weakness lies in understanding deep, structured relationships. Conversely, GraphRAG offers superior capabilities for reasoning, tracing cause-effect relationships, and following complex chains of information, but it’s more complex to build and maintain.
The true potential for enhancing LLM context lies in a hybrid approach that combines the strengths of both VectorRAG and GraphRAG. By integrating vector-based semantic search with knowledge graph-based relational querying, developers can hit the sweet-spot by creating RAG systems that are both fast and deeply insightful. The process should begin with vector search; to quickly identify the relevant content of a user’s query, this is crucial for initiating a conversation with an LLM. Once the relevant topics or entities are identified, the knowledge graph can take over to provide further and deeper insights; traversing the relationships to provide a comprehensive and connected narrative. This hybrid model ensures that LLMs not only retrieve relevant information but also understand and present the broader context, leading to more accurate and meaningful responses.
Graphshare, powered by Neo4j, harnesses the potential of this hybrid approach. Neo4j, the underlying technology, not only supports native knowledge graph functionality but also offers built-in vector search capabilities. This allows Graphshare to leverage vector search for semantic matching while utilising Neo4j’s robust graph database to map and query complex relationships. In particular LLMs can benefit from both semantic understanding and relational intelligence in a single ecosystem—giving users not just the right answers, but the full story behind them.
Enough of all the talking be ready for proof in next blog post!